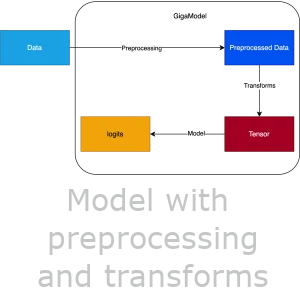
Model with all its preprocesses and transforms
Introduction
Today, I was planning to give other models a try. Each model requires its own preprocesses, train_transforms, and validation_transforms. I think of the steps of a deep learning project as below:

So, in this way of thinking, the model has no idea about preprocessing and transforms before it. Which is a really great and modular way to think about that. But when you want to try different approaches, it is a little bit troublesome.
My Approach
To solve this problem, I have defined a class called GigaModel.
This model consists of preprocessors, train_transforms, validation_transforms.
It is like a bundle, and in the future, when I look at the charts, I can
track the approach that I used way better.
So, the method looks like something below:

The code for it is like below:
class GigaModel:
def __init__(
self,
cfg: DictConfig,
device: str = "cuda",
checkpoint_path: Path = None,
):
self.cfg = cfg
self.device = device
self.checkpoint_path = checkpoint_path
self.model = self.get_model()
self.model = self.prepare_model(self.model)
self.prs = self.get_prs()
self.train_transforms = self.get_train_transforms()
self.val_transforms = self.get_val_transforms()
self.target_transform = self.get_target_transform()
def get_model(self):
model = TransformerTCN.from_config(self.cfg)
return model
def prepare_model(self, model: nn.Module) -> nn.Module:
model = model.to(self.device)
if self.checkpoint_path is not None:
model.load_state_dict(torch.load(self.checkpoint_path))
print("^" * 10, "checkpoint loaded")
return model
def get_prs(self) -> list[Callable]:
prs = [
DropUnnecessaryColumns.from_config(self.cfg),
FillNulls.from_config(self.cfg),
ShrinkSequence.from_config(self.cfg),
SortData.from_config(self.cfg),
AddGlobalFeatures.from_config(self.cfg),
AddMagnitude.from_config(self.cfg),
NormalizeScaler.from_config(self.cfg),
]
return prs
def get_train_transforms(self) -> list[Callable]:
train_transforms = [
TTCNTransform.from_config(self.cfg),
]
return train_transforms
def get_val_transforms(self) -> list[Callable]:
val_transforms = [
TTCNTransform.from_config(self.cfg),
]
return val_transforms
def get_target_transform(self) -> NormalTargetTransform:
target_transform = NormalTargetTransform.from_config(self.cfg)
return target_transform
def predict_sequence(self, sequence: pl.DataFrame):
for pr in self.prs:
sequence = pr(sequence)
for transform in self.val_transforms:
sequence = transform(sequence)
model_device = next(self.model.parameters()).device
self.model.eval()
with torch.inference_mode():
sequence = [x.to(model_device) for x in sequence]
sequence = [x.unsqueeze(0) for x in sequence]
prediction = self.model(sequence)
return prediction
def prediction_to_label(self, prediction):
prediction = prediction.squeeze().argmax().item()
return self.target_transform.label_int_to_category[prediction]
def get_giga_model(
cfg: DictConfig,
device: str = "cuda",
checkpoint_path: Path = None,
) -> GigaModel:
return GigaModel(
cfg=cfg,
device=device,
checkpoint_path=checkpoint_path,
)
As you can see, if I want to create a new approach,
the only thing that I need to do is to abstract from GigaModel
and replace only the get_* functions.
For example, for my Convolutional model, which uses Time of flight data,
I should write something like below:
class GigaTofConv1(GigaModel):
def __init__(
self,
cfg: DictConfig,
device: str = "cuda",
checkpoint_path: Path = None,
):
super().__init__(cfg, device, checkpoint_path)
def get_model(self) -> nn.Module:
return TofConv1.from_config(self.cfg)
def get_prs(self) -> list[Callable]:
prs = [
DropUnnecessaryColumns.from_config(self.cfg),
DropNulls.from_config(self.cfg),
ShrinkSequence.from_config(self.cfg),
SortData.from_config(self.cfg),
ChangeTOFTo2D.from_config(self.cfg),
]
return prs
def get_train_transforms(self) -> list[Callable]:
train_transforms = [
TOFTransform.from_config(self.cfg),
]
return train_transforms
def get_val_transforms(self) -> list[Callable]:
val_transforms = [
TOFTransform.from_config(self.cfg),
]
return val_transforms
def get_giga_model(
cfg: DictConfig,
device: str = "cuda",
checkpoint_path: Path = None,
) -> GigaModel:
return GigaTofConv1(
cfg=cfg,
device=device,
checkpoint_path=checkpoint_path,
)
As shown in the code above, I have only rewritten the functions which
were needed.
The get_giga_model function for every approach that I make is a way to have
dependency injection.
The names of all functions are the same; I only change the import.
Final thoughts
I think putting all the actions which is needed for a model to create
the result that is intended to create is a good technique.
My code is still modular, because models, preprocesses, and transforms
work separately, but they are in a bundle that I can use multiple times.